微架构
在计算机工程中,微架构(有时缩写为µarch或uarch)是对计算机、中央处理单元或数字信号处理器的电路的描述,足以完全描述硬件的运行。 学者们使用 "计算机组织 "这一术语,而计算机行业的人们更经常说 "微架构"。微架构和指令集架构(ISA)一起构成了计算机架构的领域。
在计算机工程中,微架构(有时缩写为µarch或uarch)是对计算机、中央处理单元或数字信号处理器的电路的描述,足以完全描述硬件的运行。
学者们使用 "计算机组织 "这一术语,而计算机行业的人们更经常说 "微架构"。微架构和指令集架构(ISA)一起构成了计算机架构的领域。
图片库
1 图片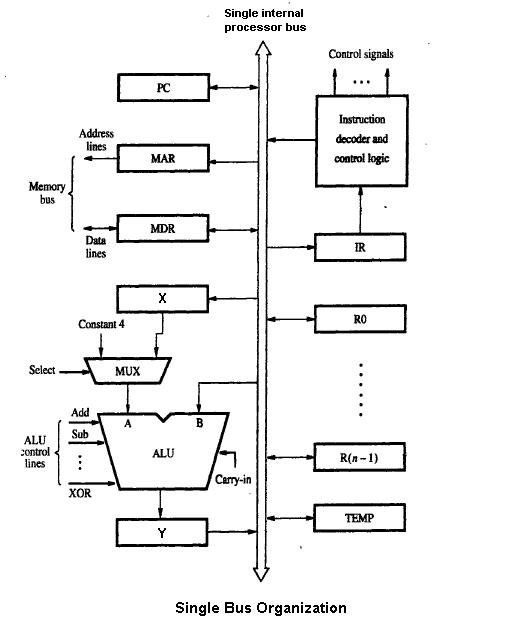
术语的起源
与指令集架构的关系
微架构与指令集架构有关,但不相同。指令集架构接近于汇编语言程序员或编译器编写者所看到的处理器的编程模型,其中包括执行模型、处理器寄存器、内存地址模式、地址和数据格式等。微架构(或计算机组织)主要是一个较低层次的结构,因此管理大量隐藏在编程模型中的细节。它描述了处理器的内部零件,以及它们如何一起工作,以实现架构规范。
微架构元素可以是一切,从单一的逻辑门,到寄存器、查找表、多路复用器、计数器等,到完整的ALU、FPU甚至更大的元素。电子电路层面又可以细分为晶体管层面的细节,如使用哪些基本的门结构,选择哪些逻辑实现类型(静态/动态、相位数等),此外还包括实际使用的逻辑设计构建它们。
几个重要的观点。
- 一个单一的微架构,特别是如果它包括微代码,可以通过改变控制存储的方式来实现许多不同的指令集。然而,这可能是相当复杂的,即使通过微代码和/或ROM或PLA中的表结构来简化。
- 两台机器可能有相同的微架构,因此有相同的框图,但硬件实现完全不同。这既管理着电子电路的水平,更管理着制造的物理水平(包括集成电路和/或分立元件)。
- 具有不同微架构的机器可能具有相同的指令集架构,因此都能够执行相同的程序。新的微架构和/或电路解决方案,以及半导体制造的进步,是使新一代的处理器实现更高的性能的原因。
简化描述
一个非常简化的高层描述--在市场营销中很常见--可能只显示相当基本的特征,如总线宽度,以及各种类型的执行单元和其他大型系统,如分支预测和高速缓冲存储器,被描绘成简单的块--也许会注明一些重要的属性或特征。一些关于管道结构的细节(如获取、解码、分配、执行、回写)有时也可能被包括在内。
微体系结构的方方面面
管道式数据通路是当今微架构中最常用的数据通路设计。这种技术被用于大多数现代微处理器、微控制器和DSP中。流水线架构允许多条指令重叠执行,很像一条装配线。流水线包括几个不同的阶段,是微架构设计的基础。其中一些阶段包括指令获取、指令解码、执行和回写。一些架构还包括其他阶段,如内存访问。管线的设计是微架构的核心任务之一。
执行单元对于微架构也是至关重要的。执行单元包括算术逻辑单元(ALU)、浮点单元(FPU)、加载/存储单元和分支预测。这些单元执行处理器的操作或计算。选择执行单元的数量、其延迟和吞吐量是重要的微架构设计任务。系统内存储器的大小、延迟、吞吐量和连接性也是微架构的决定。
系统级的设计决定,如是否包括外设,如内存控制器,可以被认为是微架构设计过程的一部分。这包括对这些外设的性能水平和连接性的决定。
与架构设计不同,具体的性能水平是主要目标,微架构设计更密切地关注其他限制因素。必须注意以下问题。
- 芯片面积/成本。
- 功率消耗。
- 逻辑的复杂性。
- 易于连接。
- 可制造性。
- 调试的便利性。
- 可测试性。
微结构概念
一般来说,所有的CPU、单芯片微处理器或多芯片实现通过执行以下步骤来运行程序。
- 读取一条指令并解码。
- 找到处理指令所需的任何相关数据。
- 处理该指令。
- 把结果写出来。
使这一系列看似简单的步骤复杂化的是,内存层次结构,包括缓存、主内存和非易失性存储,如硬盘,(程序指令和数据所在)一直比处理器本身慢。步骤(2)在数据通过计算机总线到达时,往往会引入一个延迟(在CPU术语中通常称为 "停顿")。大量的研究已经被投入到尽可能避免这些延迟的设计中。多年来,一个核心设计目标是并行执行更多指令,从而提高程序的有效执行速度。这些努力引入了复杂的逻辑和电路结构。在过去,由于这些技术需要大量的电路,这些技术只能在昂贵的大型机或超级计算机上实现。随着半导体制造的进步,越来越多的这些技术可以在单个半导体芯片上实现。
下面是对现代CPU中常见的微架构技术的调查。
指令集选择
选择使用哪种指令集架构,对实现高性能设备的复杂性影响很大。多年来,计算机设计者尽力简化指令集,以便通过节省设计者的精力和时间来实现提高性能的功能,而不是把它们浪费在指令集的复杂性上,从而实现更高的性能。
指令集设计已经从CISC、RISC、VLIW、EPIC类型发展到了现在。处理数据并行的架构包括SIMD和Vectors。
指令流水线
最早,也是最强大的提高性能的技术之一是使用指令流水线。早期的处理器设计在进入下一条指令之前,对一条指令进行了上述所有的步骤。处理器电路的大部分在任何一个步骤中都是空闲的;例如,指令解码电路在执行期间是空闲的,等等。
管道通过允许一些指令同时在处理器中工作来提高性能。在同一个基本例子中,当上一条指令在等待结果时,处理器将开始解码(第1步)新指令。这将允许多达四个指令同时 "飞行",使处理器看起来快了四倍。尽管任何一条指令都需要同样长的时间来完成(仍然有四个步骤),但CPU作为一个整体 "退 "掉指令的速度要快得多,可以以更高的时钟速度运行。
缓存
芯片制造的改进使得更多的电路可以被放置在同一芯片上,设计者开始寻找使用这些电路的方法。最常见的方法之一是在芯片上增加越来越多的高速缓冲存储器。缓存是一种非常快的存储器,与与主存储器对话所需的时间相比,可以在几个周期内访问的存储器。CPU包括一个缓存控制器,它可以自动从缓存中进行读写,如果数据已经在缓存中,它就会简单地 "出现",而如果没有,处理器就会在缓存控制器读入数据时 "停顿"。
RISC设计在20世纪80年代中后期开始增加高速缓存,通常总共只有4KB。随着时间的推移,这个数字不断增加,现在典型的CPU大约有512KB,而更强大的CPU则有1或2甚至4、6、8或12MB,在内存层次结构的多个层面上组织起来。一般来说,更多的高速缓存意味着更多的速度。
缓存和流水线是彼此的完美结合。以前,建立一个可以比片外现金存储器的访问延迟更快运行的流水线并没有什么意义。而使用片上缓存意味着流水线可以以缓存访问延迟的速度运行,时间长度要小得多。这使得处理器的工作频率能够以比片外存储器快得多的速度增加。
分支预测和投机执行
管道停滞和因分支而导致的刷新是阻碍通过指令级并行化实现更高的性能的两个主要因素。从处理器的指令解码器发现它遇到了一个条件性的分支指令,到决定性的跳转寄存器值可以被读出,流水线可能会停滞几个周期。平均来说,每执行五条指令就有一条是分支,所以这是一个很高的停顿量。如果分支被执行,情况会更糟糕,因为随后所有在流水线中的指令都需要被刷新。
分支预测和投机执行等技术被用来减少这些分支惩罚。分支预测是指硬件对一个特定的分支是否会被选中进行有根据的猜测。这种猜测允许硬件预取指令,而无需等待寄存器的读取。推测性执行是一种进一步的改进,即在知道是否应该采取分支之前,沿着预测的路径执行代码。
失序执行
缓存的增加减少了由于等待数据从主内存层次中获取而造成的停顿的频率或持续时间,但并没有完全摆脱这些停顿。在早期的设计中,缓存缺失会迫使缓存控制器使处理器停顿并等待。当然,在程序中可能有一些其他的指令,其数据在这时的缓存中是可用的。失序执行允许该准备好的指令被处理,而较早的指令则在缓存中等待,然后对结果重新排序,使其看起来一切都按照程序的顺序发生。
超标量
即使有了所有增加的复杂性和支持上述概念所需的门,半导体制造的改进很快允许使用更多的逻辑门。
在上面的概要中,处理器一次处理一条指令的部分内容。如果同时处理多条指令,计算机程序的执行速度会更快。这就是超标量处理器通过复制功能单元(如ALU)实现的。只有当单个处理器的集成电路(有些时候称为 "芯片")面积不再延伸到可以可靠制造的极限时,功能单元的复制才成为可能。到80年代末,超标量设计开始进入市场。
在现代设计中,常见的是两个加载单元、一个存储单元(许多指令没有结果需要存储)、两个或更多的整数数学单元、两个或更多的浮点单元,而且通常还有一个某种SIMD单元。通过从内存中读入大量的指令列表,并将其交给当时闲置的不同执行单元,指令发布逻辑的复杂度就会增加。然后收集结果并在最后重新排序。
寄存器重命名
寄存器重命名指的是一种技术,用于避免程序指令因被这些指令重复使用相同的寄存器而产生不必要的串行执行。假设我们有几组指令要使用同一个寄存器,其中一组指令先执行,把寄存器留给另一组,但如果另一组指令被分配到不同的类似寄存器,两组指令就可以并行执行。
多处理和多线程
由于CPU工作频率和DRAM访问时间之间的差距越来越大,在一个程序中增强指令级并行性(ILP)的技术都无法克服从主存储器中获取数据时出现的长时间停顿(延迟)。此外,更先进的ILP技术所需的大晶体管数量和高工作频率需要的功率耗散水平不再是廉价的冷却方式。由于这些原因,新一代的计算机已经开始利用存在于单个程序或程序线程之外的更高水平的并行性。
这种趋势有时被称为 "吞吐量计算"。这种想法起源于大型机市场,当时在线交易处理强调的不仅仅是一个交易的执行速度,而是同时处理大量交易的能力。随着基于交易的应用,如网络路由和网站服务在过去十年中大大增加,计算机行业重新强调了容量和吞吐量问题。
实现这种并行性的一种技术是通过多处理系统,即具有多个CPU的计算机系统。在过去,这是高端主机的专利,但现在小规模(2-8个)多处理器服务器已成为小型企业市场的普遍现象。对于大型企业,大规模(16-256)多处理器很常见。甚至自20世纪90年代以来,也出现了带有多CPU的个人电脑。
半导体技术的进步缩小了晶体管的尺寸;多核CPU出现了,在同一硅片上实现了多个CPU。最初用于针对嵌入式市场的芯片,更简单和更小的CPU将允许在一块硅片上实现多个实例化。到2005年,半导体技术允许双高端桌面CPU的CMP芯片被批量制造。一些设计,如UltraSPARC T1,使用了更简单的(标量、内序)设计,以便在一块硅片上容纳更多的处理器。
最近,另一项变得更加流行的技术是多线程。在多线程中,当处理器必须从缓慢的系统内存中获取数据时,处理器不是停滞不前等待数据的到来,而是切换到另一个准备执行的程序或程序线程。虽然这并不能加快某个程序/线程的速度,但它通过减少CPU的空闲时间来提高整个系统的吞吐量。
在概念上,多线程相当于操作系统层面的上下文切换。不同的是,多线程CPU可以在一个CPU周期内完成线程切换,而不是上下文切换通常需要数百或数千个CPU周期。这是通过为每个活动线程复制状态硬件(如寄存器文件和程序计数器)来实现的。
相关页面
问题与解答
问:什么是微架构?
答:微架构是对计算机、中央处理单元或数字信号处理器的电路的描述,足以完全描述硬件的运行。
问:学者们是如何提及这一概念的?
答:学者们在提到微架构时使用 "计算机组织 "一词。
问:计算机行业的人是如何提及这一概念的?
答:计算机行业的人在提到这个概念时更多地是说 "微架构"。
问:哪两个领域构成了计算机体系结构?
答:微架构和指令集架构(ISA)共同构成了计算机架构领域。
问:ISA代表什么?
答:ISA是指令集结构的缩写。
问:µarch代表什么?答:µArch是指微架构。
相关文章
作者
AlegsaOnline.com 微架构 Leandro Alegsa
URL: https://zh.alegsaonline.com/art/64586
来源
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture